






目次
正規表現で、24文字のブロックを抽出
こんにちは。伊川(@naonaoke)です。
今回は、正規表現について説明します。
- 文字列の集合を一つの文字列で表現する方法
- 文字列のパターンを表現する表記法
- 通常の文字 (a ~ z など) と、”メタキャラクタ” という特殊文字から構成される文字列のパターン
- 様々な文字列を一つの文字列で表現する表記法です。
Apple orange grape lemonは、[a-z]+ で表現できます。
VBA以外でも利用されている
Like演算子よりも正確に判定可能
この正規表現は、詳しく説明している書籍があまりありませんが、下記の書籍に記載があります。

今回のお題

赤枠の24文字のみ抽出という事です。
ちなみに、セルA1にすべてが、収納されています。
なんて、不親切なのでしょう?
上の図は、毎週送付される競馬のデータです。
区切りは、バラバラ、どのように区切るのかが、当時の私にはわかりませんでした。
また、Left関数、Right関数、Mid関数も役に立ちそうにありません。
正規表現の一覧は下記になります。
| 位置マッチング | |
| ^ | 文字列の先頭にのみマッチします。 |
| $ | 文字列の末尾にのみマッチします。 |
| \b | 任意の単語境界にマッチします。 |
| \B | 任意の単語境界以外の位置にマッチします。 |
| リテラル | |
| 英数字 | 英字と数字に文字どおりにマッチします。 |
| \n | 改行にマッチします。 |
| \f | フォーム フィードにマッチします。 |
| \r | キャリッジ リターンにマッチします。 |
| \t | 水平タブにマッチします。 |
| \v | 垂直タブにマッチします。 |
| \? | ? にマッチします。 |
| \* | * にマッチします。 |
| \+ | + にマッチします。 |
| \. | . にマッチします。 |
| \| | | にマッチします。 |
| \{ | { にマッチします。 |
| \} | } にマッチします。 |
| \\ | \ にマッチします。 |
| \[ | [ にマッチします。 |
| \] | ] にマッチします。 |
| \( | ( にマッチします。 |
| \) | ) にマッチします。 |
| \xxx | 8進数 xxx によって表現されるASCII文字にマッチします。 |
| \xdd | 16進数 dd によって表現されるASCII文字にマッチします。 |
| \uxxxx | UNICODE xxxx によって表現されるASCII文字にマッチします。 |
| 文字クラス | |
| [xyz] | 文字セットに含まれている任意の1文字にマッチします。 |
| [^xyz] | [^xyz] 文字セットに含まれていない任意の1文字にマッチします。 |
| . | \n 以外の任意の文字にマッチします。 |
| \w | 単語に使用される任意の文字にマッチします。[a-zA-Z_0-9]と等価。 |
| \W | 単語に使用される文字以外の任意の文字にマッチします。[^a-zA-Z_0-9]と等価。 |
| \d | 任意の数字にマッチします。[0-9]と等価。 |
| \D | 任意の数字以外の文字にマッチします。[^0-9]と等価。 |
| \s | 任意のスペース文字にマッチします。[ \t\r\n\v\f]と等価。 |
| \S | 任意の非スペース文字にマッチします。[^ \t\r\n\v\f]と等価。 |
| 繰り返し | |
| {x} | 正規表現のちょうど x個の直前の文字にマッチします。 |
| {x,} | 正規表現のx個以上の直前の文字にマッチします。 |
| {x,y} | 正規表現のx個以上、y個以下の直前の文字にマッチします。 |
| ? | ゼロ個または1個の直前の文字にマッチします。{0,1}と等価。 |
| * | ゼロ個以上の直前の文字にマッチします。{0,}と等価。 |
| + | 1個以上の直前の文字にマッチします。{1,}と等価。 |
| 選択とグループ化 | |
| () | 複数の句をグループ化して、1つの句を作成します。ネストすることができます。 "(ab)?(c)" は "abc" または "c" にマッチします。 |
| | | 選択は、複数の句を1つの正規表現にまとめ、これらのうちの任意の句にマッチします。 |
| 後方参照 | |
| ()\n | n番目の括弧で囲まれた句にマッチします。 |
| プロパティ | 説明 |
| Pattern | 検索するパターンを設定する |
| IgnoreCase | 検索するときに大文字と小文字を区別する(既定値:False)か、区別しない(True)かを設定する |
| Global | 検索文字列全体について検索する(True)か、最初の一致を検索する(既定値:False)のかを設定する |
| RegExpオブジェクト | |
| Pattern | 検索するパターンを設定する |
| IgnoreCase | 検索するときに大文字と小文字を区別する(既定値:False)か、区別しない(True)かを設定する |
| Global | 検索文字列全体について検索する(True)か、最初の一致を検索する(既定値:False)のかを設定する |
| Test | object.Test(string) パターンに一致する文字列が検索されたらTrueを返します。 見つからないとFalseを返します。 |
| Replace | object.Replace(string1, string2) 検索されたら置換文字列(string2)と置き換えます。 |
| Execute | object.Execute(string) 指定された文字列を正規表現で検索します 文字列内で見つかった文字列ごとに存在するMatchオブジェクトを含む、Matchesコレクションを返します。 |
正規表現で抽出 作業手順 その1 データベース確認

このようなデータが、今回は、466行並んでいます。
正規表現で抽出 作業手順 その2 今回使う変数

RegExは、Objectを格納する変数です。

いつものやつです。
A列の最期までという意味です。
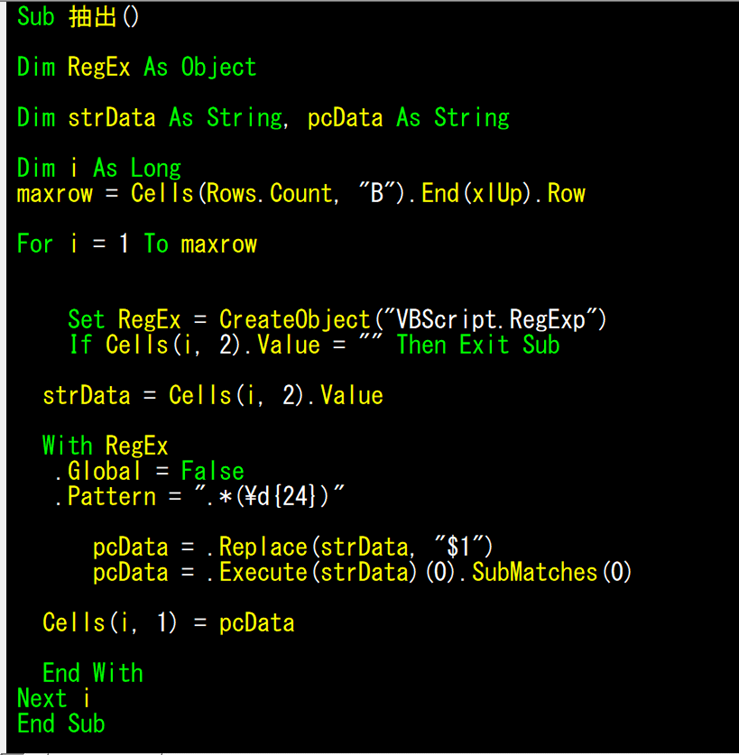
正規表現で抽出 作業手順 その3 正規表現で抽出するコード

正規表現で新しく作成した値を、RegExにセットします。
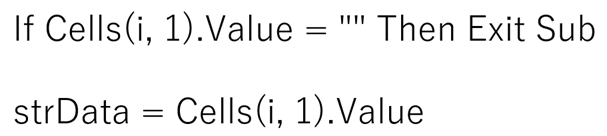
Cells(i,1)が、空だったら、条件から抜ける。
空ではなければ、strDataにCells(i,1)の値を代入する。

この部分が肝となります。
上に掲載した、正規表現のパターンを参照しながら確認してください。
ざっくばらんに説明しますと、
.Pattern = “.*(\d{24})”が、24文字のブロックを探します。
当然24文字のブロック(001003000202007032018540 )は存在します。
存在するからReplaceで、正規表現でマッチングした値に置換します。
置換された値は、Executeが作動して、その結果をSubMatchesに送ります。
SubMatches
正規表現で検索を実行すると、サブ条件が取得を示すかっこで囲まれている場合にサブマッチ文字列が 0 個以上作成されます。

あとは、値をセルに表現するだけです。
これで完成です。
配列で抽出 作業手順 その4
Split関数を使う
今まで、このような整形されていないデータをエンジニアの人はどのように整形するのかと思っていました。
しかし、勉強をしていると、突然閃きます。
つまり、乗れなかった自転車が突然、乗れるようになるのと同じです。


特定の文字(空白も含む)で区切られていたら、Split関数で配列に格納できます。
配列とExcelは相性がいいですよね。
このような場面で配列を利用する場面が現れます。
Sub スペースごとに配列変数に格納する() Dim arr As Variant Dim tmp As String tmp = ActiveCell.Value tmp = Replace(tmp, " ", " ") arr = Split(tmp) Stop End Sub
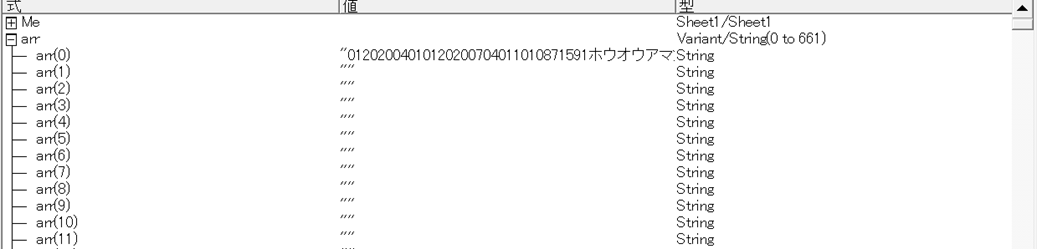
このように、すべて配列に格納されます。
全部で662個のハコに格納されます。
配列がわからなくても勉強していくと、突然、このような場面に遭遇します。
後は、配列をセルに表現するだけです。
結構な長さですが、Excelは対応できますので、安心してください。
ここがポイント

今回は、正規表現を紹介しました。難しいのですが、正規表現を改めて勉強したときに、理屈を理解できました。そして、みなさんに、配列を紹介したことをキッカケに、Split関数の利用方法を改めて理解しました。勉強は続けていくと、いくつもの感動に出会うものです。
まとめ
今回は、正規表現をメインに紹介しましたので、Split関数の部分は少し割愛しました。
この続きは、機会を見て紹介したいと思います。
また、今回は、競馬のデータを利用しています。
著作権を侵害する可能性がありますので、サンプルファイルはお渡しできませんので、ご了承ください。
今回のサンプルファイルはありません。

わからない事を延々と考えるのは、無駄です。
- なんで作動かないの?
- もうやだ!VBAなんか嫌い!
- ネットで調べても情報がない!
必ず作動するコードが、ここにあります。








